

Data Modelling in Qlik Sense needs consideration as it is a key element to ensuring your Qlik platform is performing in the most efficient, optimised fashion.
That’s why for the latest instalment of our Qlik Best Practice series we’ve provided the basic rules for efficient Data Modelling in Qlik Sense.
Data Modelling in Qlik Sense
The goal of a Qlik data model is to enable efficient handling of the data.
We therefore recommended you follow these guidelines when building a data model in Qlik Sense:
- A normalised star-schema is the desired data model for Qlik as it is most efficient and understandable. In some cases, a snowflake-schema can be necessary, and can help manage the widths of tables, but can become inefficient as an association has to travel through intermediary tables. Flat tables (a single concatenated table) are inefficient, lacks discipline by the developer, and scalability when reusing subsets of data across multiple apps. A star-schema typical contains is a central fact table consisting of dimensional keys and numerical fields; fields that will be used for calculations e.g. Quantity, Sales amount, etc. Surrounding the fact table are dimensional tables with all the corresponding attributes, for example a product table would contain a product number, product group, product description, etc:
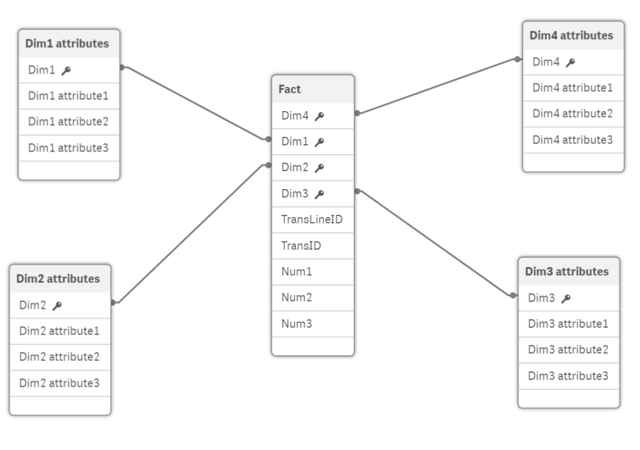
- When you’re data modelling in Qlik Sense, all data tables should be associated, and therefore data islands should be avoided – with the exception of data islands used to add further functionality (and not containing data).
- Synthetic keys should be resolved. Synthetic keys are created by Qlik when two or more data tables have two or more fields in common – suggesting a composite key relationship. While synthetic keys can be perfectly valid, and can be a great source of a debate, depending on the number of synthetic keys, data volumes and other factors, Qlik may not handle them efficiently. Ultimately, Ometis believe it is a sign of lazy development and/or a lack of understanding to resolve them. Therefore, compound fields should be created and one-or-more of the fields should be removed or renamed in one-or-more of the fields.
- Circular references should not exist within the data model as it causes uncertainties in data structure. A circular reference is a loop in the data model. Qlik Sense handles circular references by breaking the loop with a loosely-coupled table.
- Ensure link fields (fields that associate to two or more tables) are intuitively named. For simple, singular link fields this may be ‘Product Number’ as an example. For compound keys, this could be a concatenation of the field names, such as OrderHeaderLineID. This can help understand what the field is the result of, without reading the script.
- Hide compound fields and other fields not used for analysis. This can tidy-up the field list and reduce the incorrect use of fields. This can be achieved setting the HidePrefix or HideSuffix variables, using the SEARCH EXCLUDE statement or tagging fields with ‘$hidden’.
- Tables should be intuitively named – this will allow users to filter the fields list by table names more easily.
- Avoid loading data in multiple times to achieve previous-period calculations. Instead, implement a robust calendar which can achieve this more efficiently, without multiplying the data volumes. An as-of calendar is one solution for this.
- If multiple dates are used for analysis, consider implementing canonical dates with a single (master) calendar on that canonical date field. This reduces the need to have multiple independent calendars (one per date field). An additional benefit of a canonical date and a master calendar is that you can plot two measures, using different canonical dates, on the same time-series.
- Dimensional tables are typically master tables and by that definition should contain a record for every value. If the subset ratio is less than 100 per cent, it means values exist in other tables, such as the transnational/fact table that don’t exist in the dimensional table. In this case, the data architect should enquire as to why this is and append missing link values to the dimensional table, and populate the attribute fields with arbitrary values that represents missing data, such as a hyphen (‘-‘) or ‘Unknown’. Null values cannot be selected in Qlik Sense. Therefore, populating missing data with arbitrary values will enable end-users to still select and gain insights into that data.
Data Modelling in Qlik Sense is the foundation of a high-performing, efficient application. If you build your foundations correctly, it can make building your visualisations and expressions easier and perform more efficiently.
To stay up-to-date with all the latest Qlik tips and tricks please remember to follow us on LinkedIn, Twitter and YouTube.
By Chris Lofthouse



Comments