

When implementing Qlik Sense we strongly advise implementing a semantic layer, known in Qlik as a QVD layer.
The QVD layer acts as a centralised data library, which contains a collection of governed data snapshots, derived from one or more data sources. The data in a Qlik Data Library should be ‘business ready’ – meaning it should be clean, timely, accessible, formatted and easily associated. This makes it perfectly suited for true self-service analytics.
The data files are stored as a ‘.QVD’ file extension. QVD files can be used for many purposes. At least four major uses can be easily identified:
Increasing load speed
Script execution becomes considerably faster for large data sets.
Decreasing load on source systems
The amount of data fetched from external data sources can be greatly reduced. This reduces the workload on external databases and network traffic. Furthermore, when several apps share the same data, it is only necessary to load it once from the source database into a QVD file. Other apps can make use of the same data through this QVD file.
Consolidating data from multiple apps
Consolidate similar data from different business units into a single location.
Incremental load
The QVD functionality can be used for incremental load by loading only new records from a growing database.
Two-Tier Architecture
In most cases with Qlik Sense, a two-tier approach is adopted as it provides simplicity, performance and increased agility. Due to the agility, we believe it best enables a self-service environment.
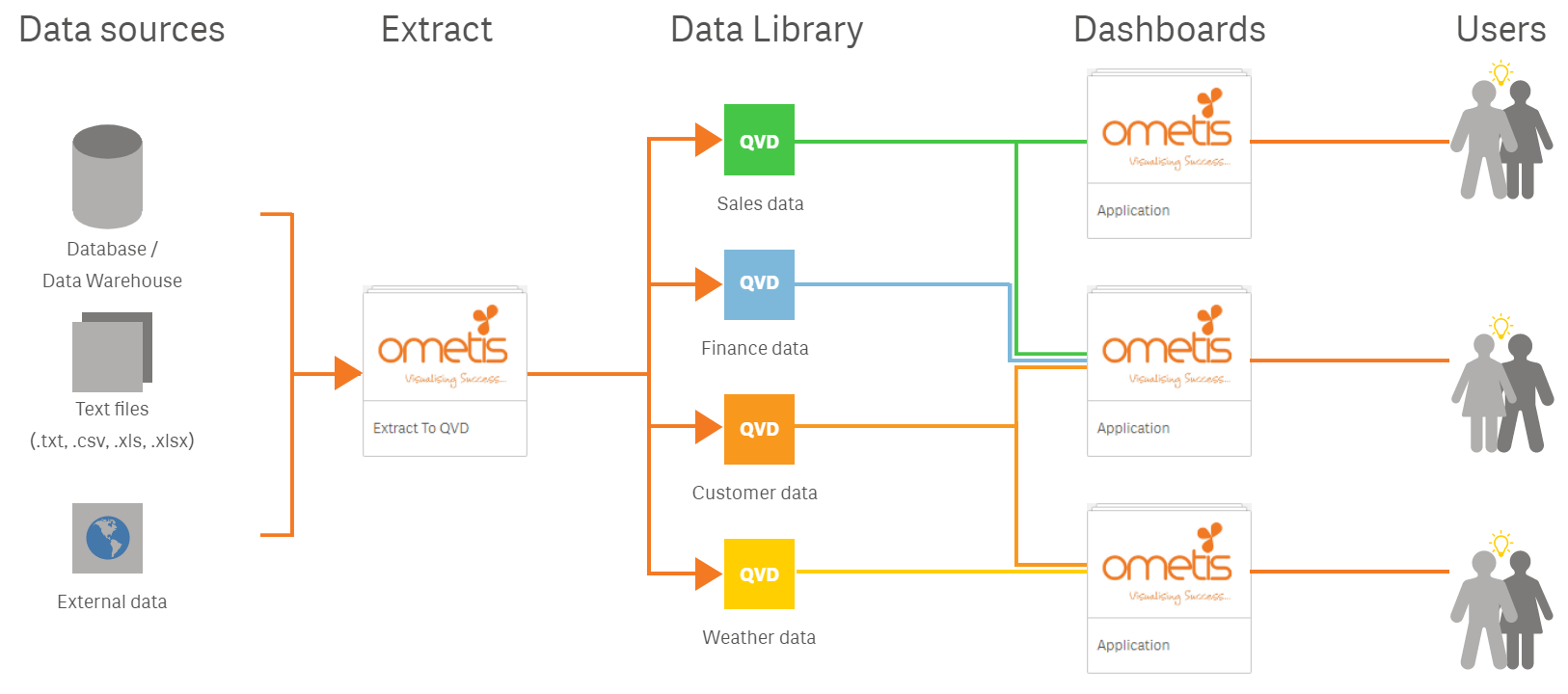
Qlik Sense two-tier architecture
In summary, a two-tier architecture will have one or more Extract applications. Extract apps are applications that do not contain any visualisations for reporting purposes. They simply connect to all necessary data sources, extract the raw data, transform the data into a business-ready format and store it into .qvd filesr. You can split the extract apps into multiple apps depending on the velocity in which the different data sources are updated and per the business’ requirements. Each QVD contains a single table of data for reporting within the UI apps (dashboards). After the data library has been created, users can then create UI apps using the governed data. As the QVDs are business-ready, the users can simply import the transformed data using the Data Manager and they shouldn’t require any scripting; the associations should have been defined by the developer by this point, so they resolve automatically.
Three-tier architecture
A three-tier architecture is most common in larger enterprises. It was also common practice in QlikView, if you are intending to use Qlik Sense for guided analytics then this approach could be more suitable.
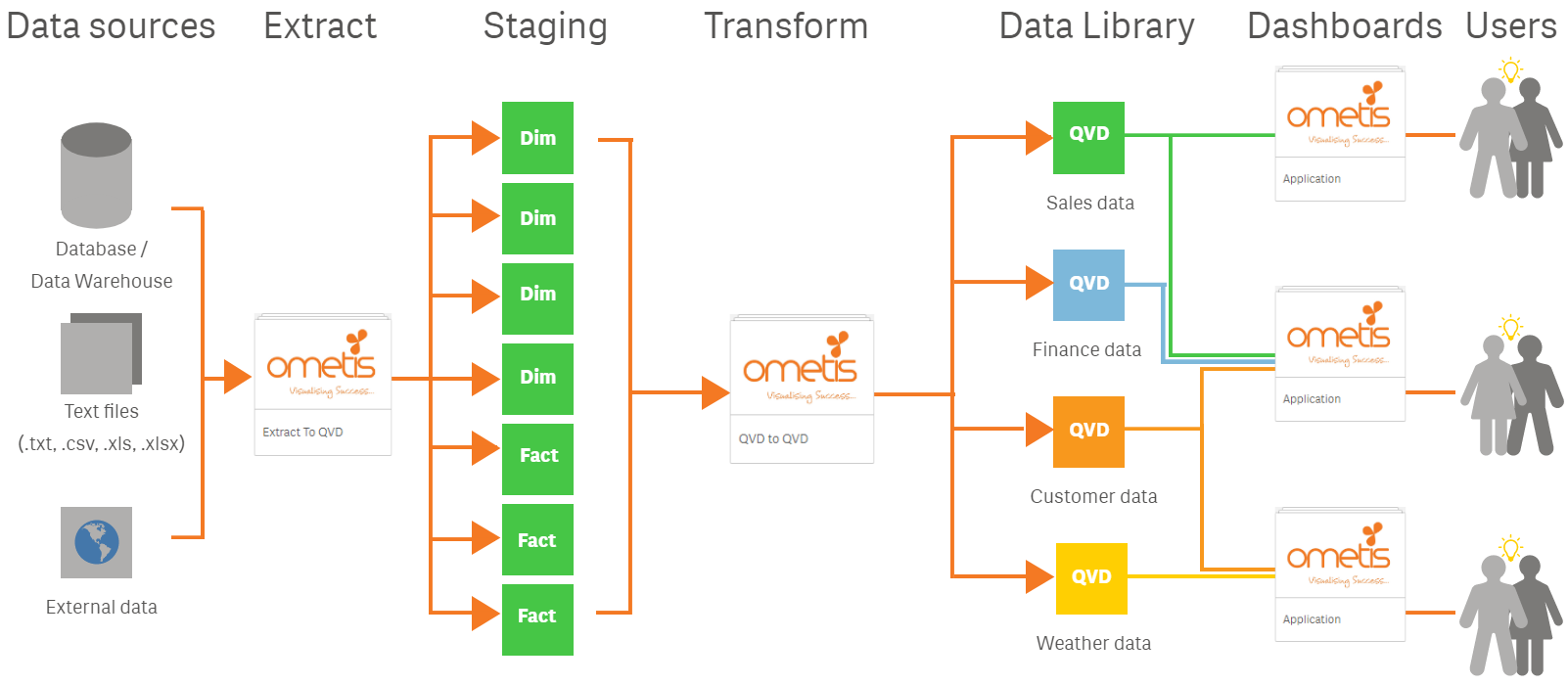
Qlik Sense three-tier architecture
A three-tier architecture works in very much the same way, the difference being that the extract and transformation processes are divided into two separate steps. A three-tier approach will utilise one or more extract applications to extract the raw data but will not perform any transformations, it simply queries and stores the information into QVDs. This reduces the impact on the live data sources by minimising the time connected. Once the initial (staging) QVDs have been created, we can then proceed to apply any transformations required to make the data suitable for reporting/dashboarding. All transformations are conducted solely in the Qlik environment and then stored to business-ready QVDs.
For more information on using QVDs, and implementing the correct architecture for your needs, get in touch with us today.
By Christopher Lofthouse
Topic: Data analytics



Comments