

When two or more data tables have two or more fields in common, this implies that there are multiple key relationships between the tables. Qlik Sense handles this through synthetic keys which represent all possible combinations of those shared fields.
I recently got a question from a client about why you should aim to resolve synthetic keys. Why can’t you have more than one key field between two tables? Well, in some cases you can. A synthetic key is not necessarily a problem in itself, but is often a symptom of an incorrect data model. As the number of synthetic keys increases, they may affect performance and cause excessive memory usage. But what does a synthetic key actually look like on the row-level and how does it affect a table? This blog post provides examples of how synthetic keys may look and when they cause issues in the data model.
Synthetic keys due to an incorrect data model
When synthetic keys are created, the data load window gives you a warning message rather than an error message. The warning suggests that you may need to investigate the key relationships and rethink your data model. Most times, in my experience, synthetic keys arise as an underlying mistake in the data model. An example of this is when you have identically named fields that are incorrectly associated with each other. Typical examples include vaguely named fields such as “Comment”, “Description” or “ID”. The fields may even contain identical values but still have different roles. Such examples include “Date”, “Name” or “Amount”. Let’s take a closer look at such examples.
1. This example shows synthetic keys that have no identical values and different roles
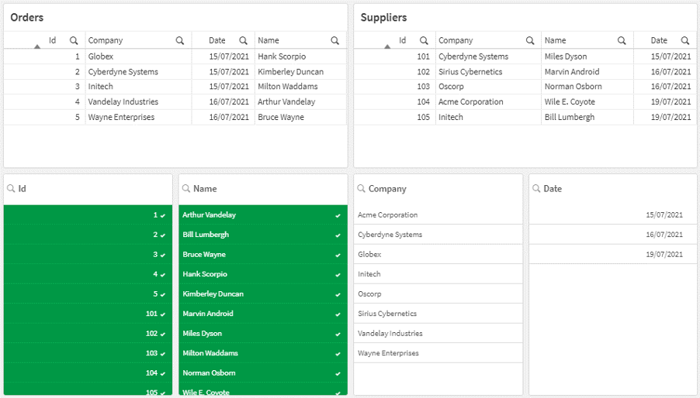
In this example, the fields “Id” and “Name” are automatically associated between the two tables “Orders” and “Suppliers” because of the identical fieldnames. However, as we can see, the two fields have no matching field values and are playing different roles. The Orders table in this case contains a sales order ID and a customer contact name, whereas the Suppliers table holds a supplier ID and a supplier contact name. There is no actual relationship between these fields and therefore an incorrect association.
2. This example shows synthetic keys that have some associated values but different roles
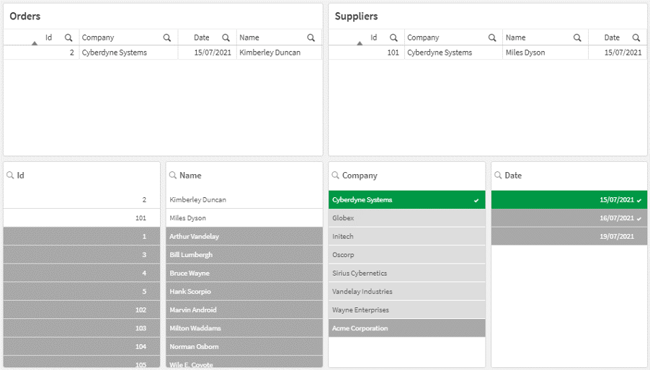
In this example, the fields “Company” and “Date” have been associated because of the identical fieldnames, and there are also a few identical field values matching between the two tables. However, the field “Company” is a customer company in the Orders table, while it’s a supplier company in the Suppliers table. Furthermore, the date fields each play a different role. The first date field represents a sales order date, whereas the second represents a supplier created date. Despite some matching field values, this is an incorrect association.
Synthetic keys that are valid
A synthetic key is not always a problem and is not always a mistake in the data model. A synthetic key may have identical field values and fulfil the same role.
1. This example shows synthetic keys that have identical values and play the same roles
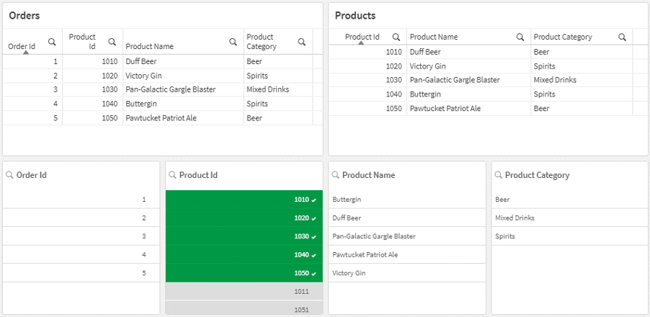
In this example, the fields “Product Id”, “Product Name” and “Product Category” are fully matching on all values and creates valid associations between the two tables. However, you may want to question if the Orders table needs to display this information for each order line, when we already have the information in the Products table. As the number of orders increases for the same products, the product fields will be repeated in the Orders table. In this case, the synthetic keys are creating data redundancy.
2. This example shows synthetic keys that have identical values and can be combined
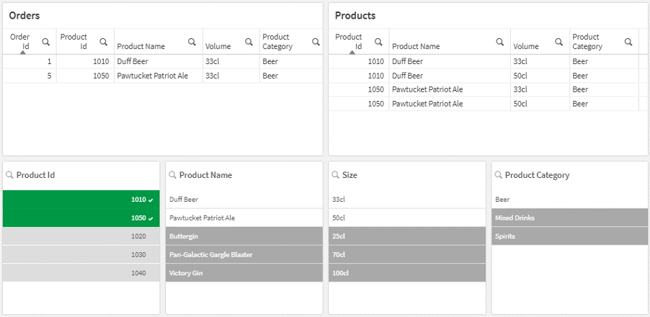
In this example, the field “Product Id” is not enough to uniquely identify the product in the Products table. The other field “Volume” is needed to determine the product more precisely whenever the product comes in multiple sizes. The synthetic keys “Product Id” and “Volume” are not causing any issues per se, but could be combined to create a single composite key that uniquely identifies each product instead of just the “Product Id”.
Resolving synthetic keys
The good news is that resolving synthetic keys is straightforward. Simply rename or remove the field causing it. In the first examples provided above, renaming the fields more specifically based on their roles would resolve the incorrect associations. For example, the fields in the Orders table could be renamed to “Order Id”, “Order Date” and so on.
When the synthetic keys are valid, they still create a synthetic table with all possible combinations of the fields. If the synthetic keys cause performance issues or data redundancy, the synthetic table can be made redundant by merging the synthetic keys to a single composite key to uniquely identify each row of data. Simply combine the fields together with the ampersand symbol “&”, as shown in this example:
[Field1]&’_’&[Field2] as [MyCompositeKeyfield]
If the key consists of many fields and starts to get long and complex, it can be reduced by using the AutoNumber function. The AutoNumber function replaces the clear-text field values with a unique integer value for each distinct key. This will reduce the number of characters used in the key field and thus decrease the size of the table.
Summary
Synthetic keys are not always an issue, but rather a warning from Qlik Sense that you may need to revise the architecture and investigate the key relationships in the data model. In many cases, as shown in this blog post, you can profitably resolve the synthetic keys to create a more specific and compact data model.
Do you want to know more about data modelling and get hands-on experience with what’s shown in this blog? Get in touch with the Ometis team today.
By: Chris Lofthouse
Topic: Data analytics



Comments